
Seit einigen Jahren verrichtet bei mir im Netz ein Raspberry Pi mit Pi-hole ausgezeichnete Dienste. Endlich kam ich dazu, einen echten Heimserver bei mir in Betrieb zu nehmen, der den Raspberry ablösen soll. Dabei setze ich auf eine absolute Low-Cost-Variante, verzichte jedoch nicht auf Virtualisierung. Insgesamt hat mich meine Lösung bisher rund 50,-€ gekostet.
Schreibe einen KommentarKategorie: Wissenswertes

Late to the Party, aber ich habe mal ChatGPT ausprobiert. Nachdem ich im letzten Jahr mit GPT3 eine Weihnachtsgeschichte in 24 Kapiteln schreiben ließ, wollte ich wissen, was ChatGPT so drauf hat.
Und was soll ich sagen? Beeindruckend, was die KI so alles weiß! Oder eben nicht weiß. Aber der Reihe nach.
Schreibe einen Kommentar
Wordle begeistert weiterhin die Benutzer auf Twitter. Was Wordle ist, habe ich bereits beschrieben. Wenn wunderbar umgesetzte Ideen plötzlich erscheinen, sprießen die Nachahmer aus dem Boden, wie Pilze nach feuchtem Wetter. Nicht alle verfolgen das Ziel Profit daraus zu schlagen. Spannend sind die Adoptionen für andere Sprachen oder auch Remixes, sprich die Kombination mit weiteren Ideen.
Schreibe einen Kommentar
Seit einiger Zeit beschäftige ich mich mit Data Science und allem was dazu gehört. Ich überlege auch schon seit geraumer Zeit, einen Newsletter zu starten. Das hat viele Gründe. Einer davon ist, dass man gezwungen ist, regelmäßig Inhalte zu einem Thema zu erstellen. Sprich: Man setzt sich selbst irgendwie unter Druck.
Das Schwerpunktthema Data entstand aus der Tatsache heraus, dass ich mich damit intensiv beschäftige und sehe, dass diese Feld noch sehr groß ist und uns in Zukunft ziemlich beschäftigen wird. Seien es KI, Big Data, Datenvisualisierung oder die Herausforderungen im täglichen Leben damit.
Der Newsletter soll keine stupide Linksammlung sein, sondern kuratierte Themen beschreibt und beinhaltet bestimmt auch Spuren meiner eigenen Meinung.
Wer Interesse hat, kann sich direkt hier anmelden! Mehr Informationen findet ihr hier.
Photo by Stephen Dawson on Unsplash
Schreibe einen KommentarIm letzten Post habe ich mich mit den Daten zu dem Corona/Covid-19-Virus beschäftigt. Dort habe ich ein paar Diagramme erstellt und (subjektive) Rückschlüsse daraus gezogen. Ein Kollege fragte mich, in Bezug auf den Vergleich zwischen den bestätigten Infektionen zwischen Deutschland und China, wie sich die Kurven im Verhältnis zur jeweiligen Bevölkerung verhalten.
Voilà, so schauts’ aus:
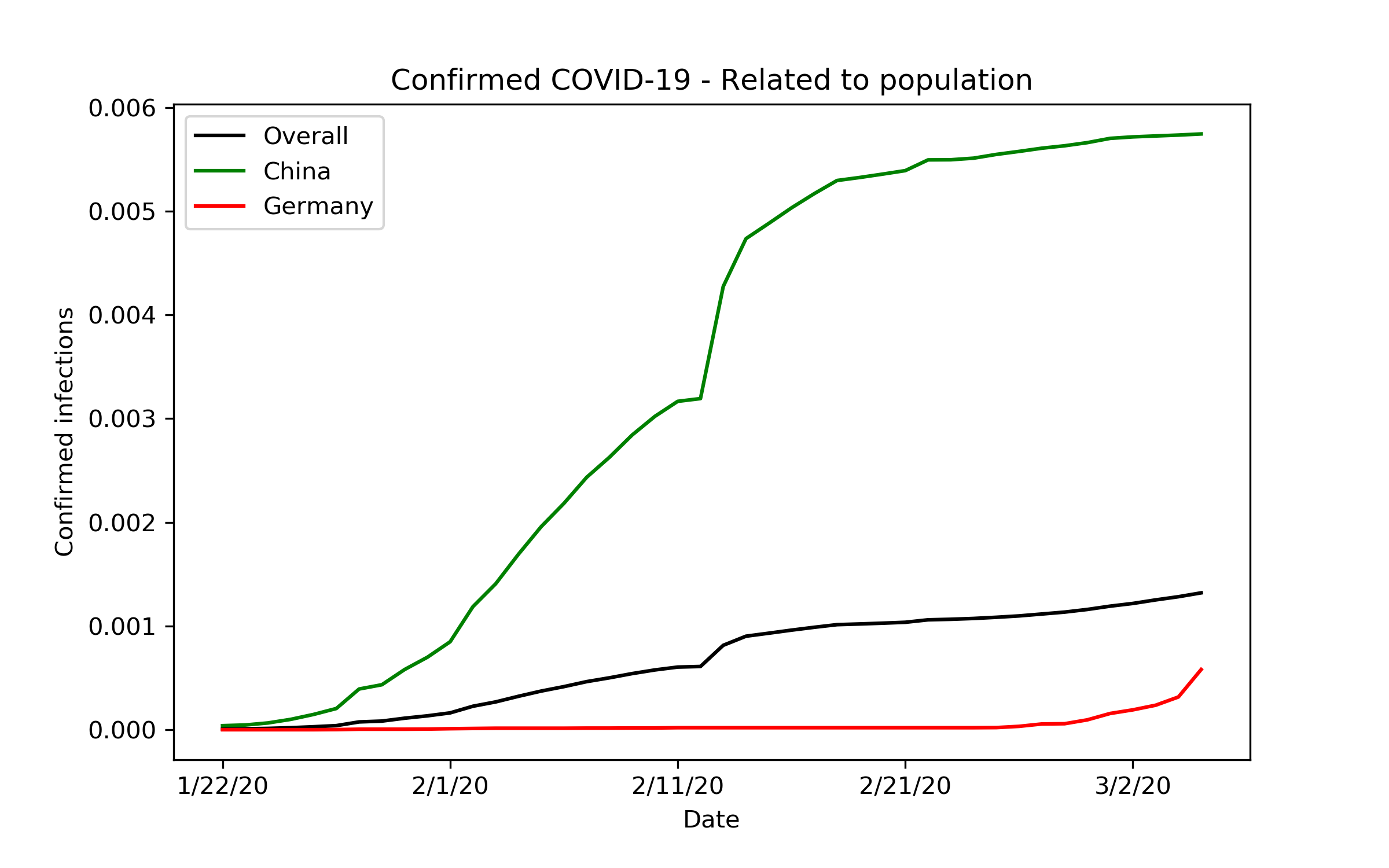
Man sieht sehr schön: In Deutschland stehen wir am Anfang eines exponentiellen Anstiegs. In Bezug auf die Gesamtbevölkerung herrschen bei uns noch nicht die gleichen Herausforderungen, wie es in China ist und war.
Auf Hinweis des gleichen Kollegen habe ich auch die Infizierten, Geheilten und Toten gegenüber gestellt. Und siehe da: Wir haben stand 05.03.2020 mehr geheilte als bestätigt infizierte.

Es bleibt abzuwarten, wie sich das Virus in Europa und Amerika entwickelt, dennoch finde ich das diese positive Entwicklung auch mal erwähnt werden muss!
Schreibe einen Kommentar
Coronavirus? COVID-19? Nichts bestimmt die News mehr als dieser Virus, gegen den bisher keine Impfung und Heilmittel bekannt ist. Trotzdem sterben daran nur die Wenigsten. Daten dazu habe ich mir mal angeschaut und für mich interpretiert.
Da ich weder über eine geeignete medizinische Ausbildung, noch in der Forschung beschäftigt bin, habe ich die Daten rein aus persönlichem Interessen analysiert und interpretiert. Alle Interpretationen sind rein subjektiv und spiegeln meine Beobachtungen wider.
Vor allem diente mir dieser Case als Übung. Zum einen, um mit Pandas und Matplotlib zu arbeiten. Zum Anderen konnte ich die Analyse von Daten inkl. der Interpretation von Daten üben. Ich stelle in dem Post meist die Zahlen aus China und Deutschland in Bezug. Hintergrund ist, dass der Virus in China eine ganz andere Verbreitung hat, als in Deutschland. Hierbei kann man einige (subjektive) Rückschlüsse ziehen.
Die Daten habe ich aus dem Github-Repository von JHU CSSE entnommen. Dort findet man zum einen eine Gesamtübersicht über alle registrierten Fälle, als auch eine zeitliche Betrachtung der Fälle, jeweils aufgeteilt in Länder und, falls vorhanden, in deren Regionen. Die Daten dort sind immer Tagesaktuell und werden aktuell gehalten. Meine Analyse basiert auf den Daten vom 02.03.2020.
Schreibe einen KommentarWas tut man heute, wenn man zu irgendwas herausfinden möchte, warum es so ist, wie es ist? Genau, man verwendet eine „KI“! Oder besser gesagt, man analysiert große Datenmengen und zieht beeindruckende Schlüsse daraus. Genau das haben Dashun Wang und seine Kollegen der Northwestern University für das Thema „the essential prerequisite for success“ (die wesentliche Voraussetzung für den Erfolg) gemacht.
Es wurden ganz viele Daten von Unternehmen untersucht, klassifiziert und seziert, um endlich zu erkennen, wie man erfolgreich sein kann. Dabei kamen so erstaunliche Erkenntnisse zutage wie:
- Jeder Gewinner startet als Verlierer
- Erfolgreiche und nicht erfolgreiche Gründer haben ungefähr gleich oft versucht ihr Ziel zu erreichen.
- Ständige Neuversuche sind nur dann erfolgreich, wenn man aus seinen vorherigen Fehlern gelernt hat
- Gescheiterte Versuche lagen meist nicht daran, dass zu wenig gearbeitet wurde
- Fail fast fail often
- Es kommt immer darauf an wie man scheitert.
Ja, so steht es in deren Paper. Mir persönlich ist nicht wirklich klar, welche neuen Erkenntnisse diese Forschung zutage gebracht hat. Man stelle sich nur mal vor, es wäre eine Zauberformel für Erfolg dabei herausgekommen. Alle Neugründungen sind Erfolge! Jeder Mensch ist erfolgreich. Geht nicht? EBEN! Sieht mal wieder ein wenig nach KI Schlangenöl aus.
Schreibe einen Kommentar
Unter Predictive Policing versteht man die Vorhersage von Straftaten. Sie dient auch dazu Wiederholungstäter vorherzusagen. Es gibt einige Firmen, die hierzu schon Computergestützte Systeme anbieten und in Deutschland wird es teilweise schon genutzt. PredPol, PRECOBS, COMPAS und wie sie alle heißen. Das Versprechen ist das Gleiche: Verbrechen vorhersagen, die Rückfallwahrscheinlichkeit nennen oder gar die Wahrscheinlichkeit nennen, an einer Schießerei beteiligt zu sein.
Schon länger wird kontrovers darüber diskutiert. Man spricht von einer Vorhersagequote von rund 67 %. Das entspricht in etwa dem Ergebnis, dass eine Gruppe von Menschen erzielen kann, würden sie einfach wahllos raten. Die zugrunde liegenden Modelle sind nicht offen. Keiner weiß, wie die Algorithmen funktionieren bzw. wie sie trainiert wurden. Es gibt bestätigte Vermutungen, dass die Systeme rassistische Tendenzen haben.
Dass ein Algorithmus auch gezielt rassistisch eingesetzt werden kann, zeigt sich in China. Ein kürzlich geleaktes Dokument beschreibt nicht nur, wie in China Menschen gezielt interniert werden. Es beschreibt ebenfalls, dass eine Software gezielt dafür eingesetzt wird, potenzielle Staatsfeinde zu ermitteln. Grundlage dafür sind die Unmengen an Daten, die über die Menschen in China durch Überwachung gesammelt werden. In China kommuniziert nahezu jeder mit WeChat und bezahlt mittels WeChat Pay. Gepaart mit der flächendeckenden Überwachung kommen einige Daten zusammen. Wird jetzt gezielt nach einer ungeliebten ethnischen Gruppe gesucht, wird einem das Ausmaß klar. Erwähnenswert ist die Tatsache, dass diese ethnische Gruppe keine Minderheit in China ist. Sie ist mit etwas mehr als 10.000.000 Menschen die viertgrößte in China.
Wie hat es Amy Webb in ihrem Buch „The Big Nine“ treffend formuliert:
The G-MAFIA* is beholden to capitalist market forces; the BAT** serves the will of the Chinese government.
Genau so ist es.
* G-MAFIA: Google, Microsoft, Apple, Facebook, IBM, Amazon
**BAT: Baidu, Alibaba, Tencent
Photo by Emiliano Bar on Unsplash
Schreibe einen Kommentar
Die Automobilindustrie ist in einem Wandel, den sie so nicht vorhergesehen hat. Jahre in der Komfortzone haben dazu geführt, dass nur noch auf Profit und nicht auf die Käufer und Benutzer ihrer Produkte geachtet wurde. Es wurde vorsätzlich betrogen und getäuscht. Dank einer guten Lobbyarbeit sind sie mit einem blauen Auge aus dem Betrug davongekommen. Viel nachhaltiger ist das Verschlafen von aktuellen Entwicklungen wie Elektromobilität, Umweltbewusstsein und Sharing Economy. Wir erleben einen enormen Wandel in der Mobilität. Manchen Menschen geht der Wandel nicht schnell genug. Doch mit einem kurzen Blick auf die Zeit, die das Automobil benötigte, um sich so tief zu etablieren, erkennt man, dass es leider nicht ganz so schnell geht.
Schreibe einen KommentarMachine Learning, Deep Learning und KI als Oberbegriff werden in den letzten paar Jahren extrem gehypt. Dass die grundlegenden Ideen, Strukturen und Algorithmen schon sehr viel länger bekannt sind, ist nicht jedem bewusst. Genauer gesagt, wird in der Forschung seit 1956 von künstlicher Intelligenz gesprochen. Neuronale Netze sind bereits in der Theorie bekannt. Die Technologie war jedoch nicht so weit. Es folgte in den 80er bis zu den 2000er der sogenannte KI-Winter. Ganz zum Erliegen kam die Forschung nicht. Im Gegenteil! 1987 hat John Walker beschrieben, wie ein neuronales Netz auf einem Commodore 64 implementiert werden kann.

In seinem Artikel beschreibt er die Funktionsweise von Neuronen und von neuronalen Netzen. Natürlich inklusive einem Beispiel mit einem Listing! Echte Fans tippen das jetzt natürlich ab, statt zu kopieren, oder?
Schreibe einen Kommentar